Login Nodes
Overview of DAIC login nodes and appropriate usage guidelines.
less than a minute
This section provides an overview of the Delft AI Cluster (DAIC) infrastructure and its comparison with other compute facilities at TU Delft.
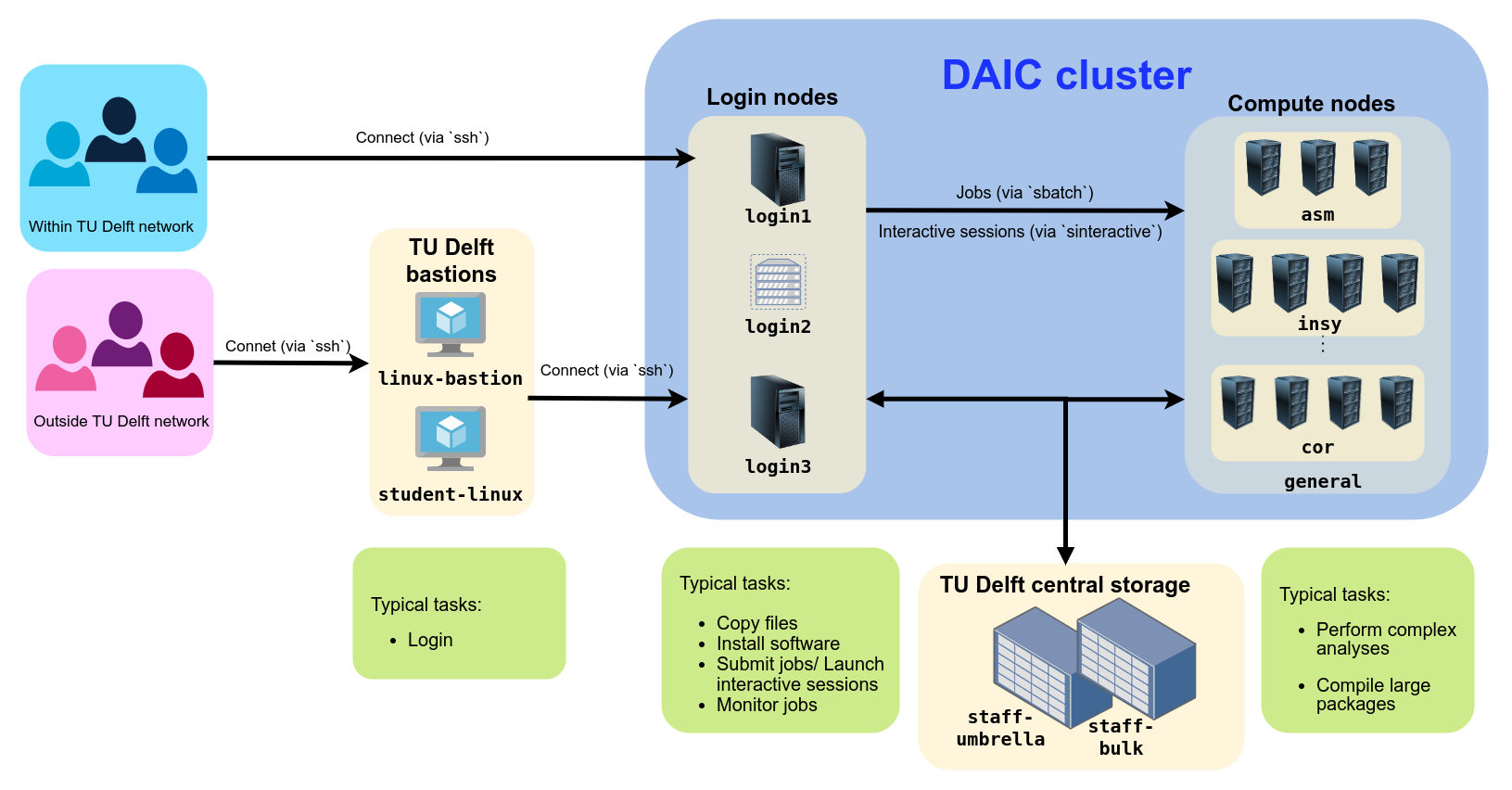
DAIC partitions and access/usage best practices
Overview of DAIC login nodes and appropriate usage guidelines.
The foundational hardware components of DAIC.
What are the foundational components of DAIC?
What are the foundational components of DAIC?
Overview of the clusters available to TU Delft (CS) researchers