Quickstart
4 minute read
General workflow
We recommend applying the following workflow when working with HPC clusters.
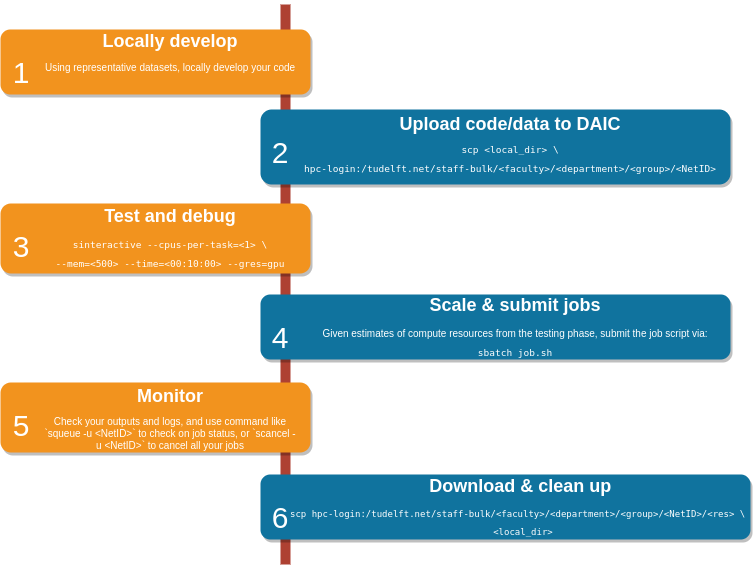
Cluster workflow, with key Unix* based commands for each step. Text within angle brackets <, > denote names that are chosen by the user
- Code is developed locally (e.g., on personal laptop or workstation),
- The code is ported to the cluster (see Connecting to DAIC and Data transfer methods).
- Possibly, software and dependencies are set up (see Software).
- Typically, code is tested on the cluster, e.g. in an interactive session (see Interactive jobs on compute nodes), following Best practices, and consulting with Support resources.
- If testing is successful, jobs scripts are submitted to the scheduler (see Job submission), and
- Progress is monitored (see Checking slurm jobs).
- Final results are downloaded for subsequent downstream analysis.
- Intermediate files are deleted (see How do I clean up tmp?)
- Check out the List of handy commands on DAIC
Quickstart
Prerequisites
- User account and credentials for DAIC (see Access and Accounts).
- Basic familiarity with the command line (see The software carpentry's Unix shell materials )
- SSH client on your local computer
Login via SSH
You can login to DAIC via SSH:
ssh <netid>@login.daic.tudelft.nl
If you are outside the TUD network you should first login to the TUD network with eduVPN. For more information about configuring SSH and the VPN, please visit How to connect to DAIC?. You will be prompted for your password:
The HPC cluster is restricted to authorized users only.
YourNetID@login.daic.tudelft.nl's password:
Last login: Mon Jul 24 18:36:23 2023 from tud262823.ws.tudelft.net
#########################################################################
# #
# Welcome to login1, login server of the HPC cluster. #
# #
# By using this cluster you agree to the terms and conditions. #
# #
# For information about using the HPC cluster, see: #
# https://login.hpc.tudelft.nl/ #
# #
# The bulk, group and project shares are available under /tudelft.net/, #
# your windows home share is available under /winhome/$USER/. #
# #
#########################################################################
18:40:16 up 51 days, 6:53, 9 users, load average: 0,82, 0,36, 0,53
YourNetID@login1:~$
Congratulations, you just logged in to the Delft AI Cluster.
Submit a job to SLURM
This section briefly describes how to submit a Python script to the queuing system SLURM. You can start by creating a Python script with some dummy-code named script.py:
import time
time.sleep(60) # Simulate some work.
print("Hello SLURM!")
Then, you can create a SLURM submission file submit.sh with the following content:
#!/bin/sh
#SBATCH --partition=general # Request partition. Default is 'general'
#SBATCH --qos=short # Request Quality of Service. Default is 'short' (maximum run time: 4 hours)
#SBATCH --time=0:05:00 # Request run time (wall-clock). Default is 1 minute
#SBATCH --ntasks=1 # Request number of parallel tasks per job. Default is 1
#SBATCH --cpus-per-task=2 # Request number of CPUs (threads) per task. Default is 1 (note: CPUs are always allocated to jobs per 2).
#SBATCH --mem=1GB # Request memory (MB) per node. Default is 1024MB (1GB). For multiple tasks, specify --mem-per-cpu instead
#SBATCH --mail-type=END # Set mail type to 'END' to receive a mail when the job finishes.
#SBATCH --output=slurm_%j.out # Set name of output log. %j is the Slurm jobId
#SBATCH --error=slurm_%j.err # Set name of error log. %j is the Slurm jobId
# Some debugging logs
which python 1>&2 # Write path to Python binary to standard error
python --version # Write Python version to standard error
# Run your script with the `srun` command:
srun python script.py
It is important to run your script with the srun command. srun is a command in SLURM used to submit and manage parallel or batch jobs on a cluster. It allocates resources, executes tasks, monitors job progress, and returns job output to users.
After creating both files script.py and sbatch.slurm you can submit the job to the queuing system with the sbatch command:
sbatch submit.sh
>>>
Submitted batch job 9267828
You can see your all your scheduled and running jobs in running with the squeue command:
squeue -u $USER
>>>
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
9267834 general script.s <netid> R 0:18 1 grs1
When your job finishes you will get a notification via email. Then you can see that two files have been created in your home directory, or in the directory where you submitted the job: slurm_9267834.out and slurm_9267834.err where the number corresponds to the job-id that SLURM had assigned to your job. You can see the content of the files with the cat command:
cat slurm_9267834.err
>>
/usr/bin/python
Python 2.7.5
cat slurm_9267834.out
>>>
Hello SLURM!
You can see that the standard output of your script has been written to the file slurm_9267834.out and the standard error was written to slurm_9267834.err. For more useful commands at your disposal have a look here.
Feedback
Was this page helpful?
Glad to hear it! Please click here to notify us. We appreciate it.
Sorry to hear that. Please click here let the page maintainers know.